Key Results
We pre-train representations on 5 unique datasets - ImageNet, Ego4D, 100 Days of Hands (DoH), Kinetics, and RoboNet - and evaluate their suitable for robotic representation learning.
Image Distribution More Important than Content
|
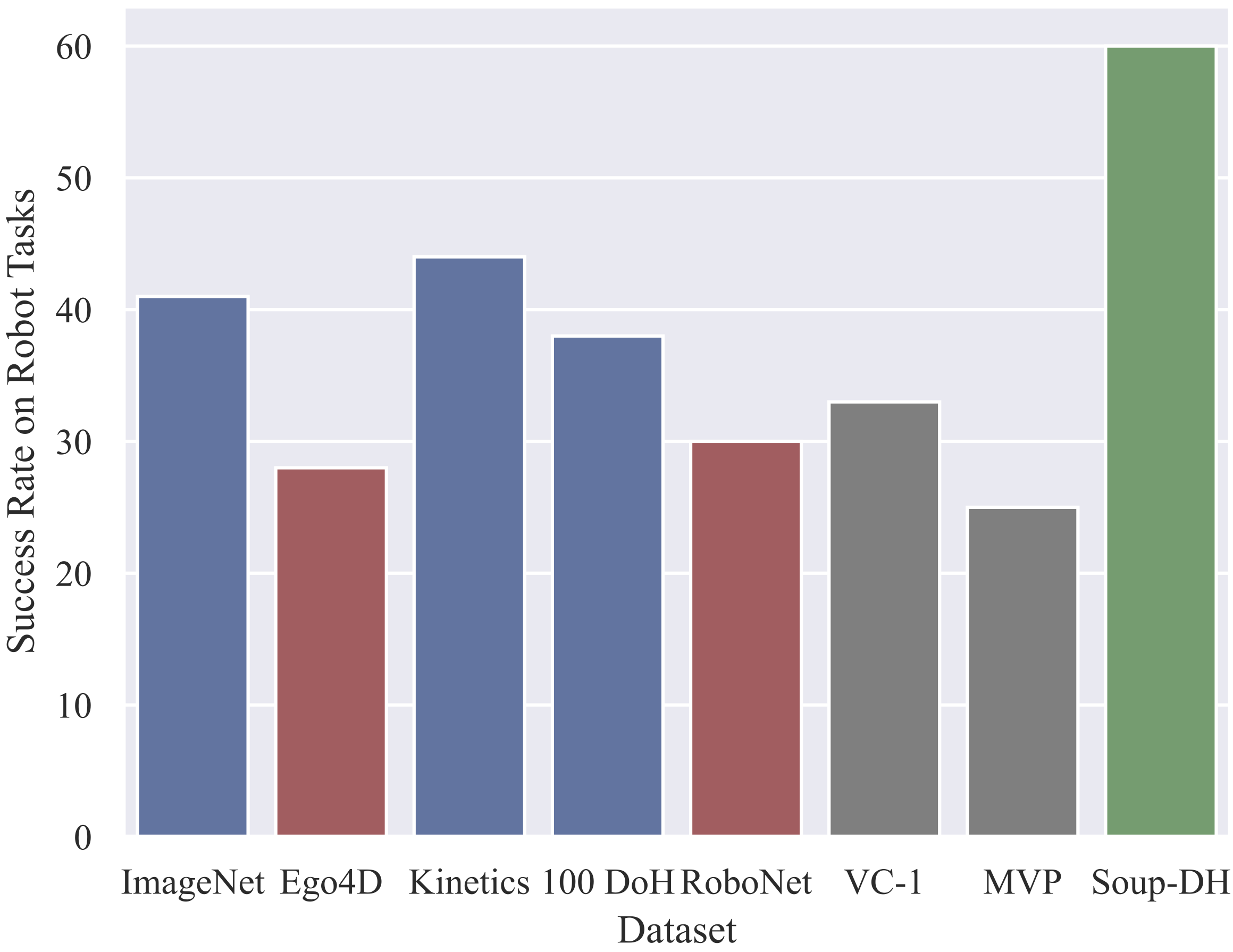
Our experiments reveal that ImageNet, Kinetics, and DoH (blue) representations all perform better than those trained on RoboNet or Ego4D (red) and prior SOTA baselines (gray). This is surprising, since both Ego4D and RoboNet seem like better matches to the test tasks -- e.g., RoboNet entirely contains images of robot interactions. These results strongly suggest that the pre-training image distribution is far more important than the images' content. We combine these insights to create a final SOUP + DoH model that exceeds all prior baselines by 30! |
|
Sim Evaluation Gives a False Sense of Progress
|
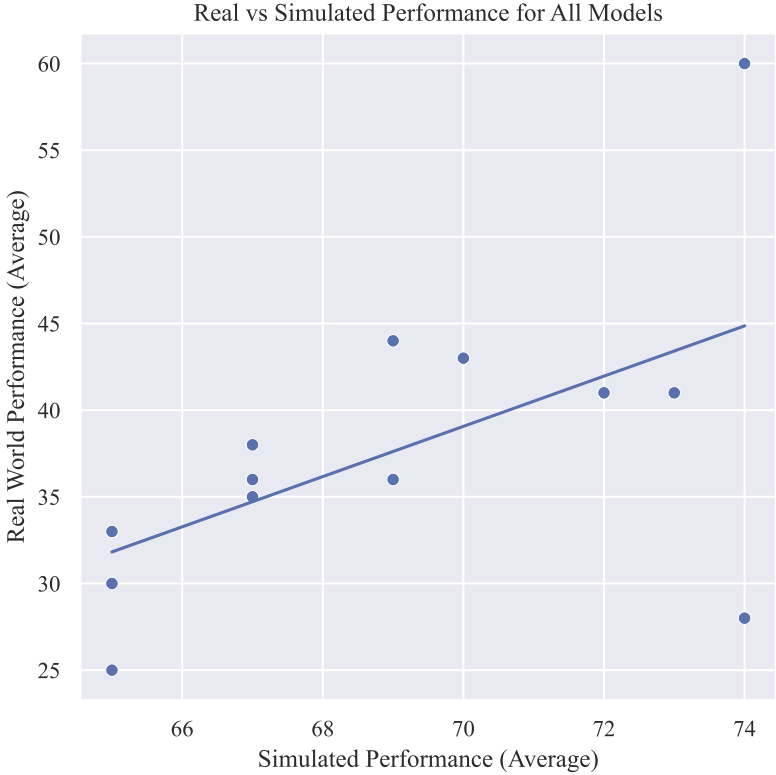
We consistently found that these (real world) results were not replicated in simulation! In fact, when the sim performance is plotted against real performance (across all models) it becomes clear that the two values are almost entirely uncorrelated: $R^2 = 32\%$. Even if you compare the two most similar sim and real tasks (RoboMimic's block-lift v.s., our stacking task) the correlation is still very low: $R^2 = 34\%$. This result is not necessarily surprising, since the sim2real gap in manipulation is well known. However, we feel it is important to explicitly do this analysis, since it's still very common practice in prior work to draw inferences about pre-trained representations using simulated benchmarks. |
|